
基于通联数据的人际关系网络构建与挖掘(网络)
基于通联数据的人际关系网络构建与挖掘(网络)
曲洋,王永剑,彭如香,姜国庆
(公安部第三研究所信息网络安全公安部重点实验室,上海201400)
摘要:网络通讯已然成为了信息时代最具代表性的产物,用户之间的社交关系也变得越来越清晰、越来越重要。文章通过模拟通联数据,利用中文分词、自然语言处理等技术构建反映人际关系的通联好友网络,并设计了一种适用于好友网络人际关系预测的多分类算法。该算法首先利用层次聚类对原始数据进行聚类并结合人工干预,确定最终类的个数,从而有效避免通联分组信息的多义词性造成的类别数过多的问题,然后以通联来往记录等信息为基础设计分类特征,最后利用在小样本下,具有复杂决策边界建模能力的支持向量机( Support VectorMachine,SVM)进行训练,得到适用于人际关系预测的分类模型,并用于未知人际关系的预测。
关键词:通联日志;人际网络:用户串并;关系预测;SVM
中图分类号:TP309 文章编号:1671-1122( 2016) 06-0068-060研究现状
在社会学、统计学和图论领域中,针对人类社会网络的研究由来已久。近年来,在网络结构、人类行为等各方面也取得了众多的科研成果,部分学者重点就社交网络节点的影响力进行了深入研究。
韩毅等人通过分析社交网络的链接结构,设计了一种基于依赖关系的支撑结构模型及计算方法并用于确定社交网络中特定节点的影响力来源。此外,吴信东等人从网络拓扑、用户行为和交互信息等几个方面总结了影响力分析的建模和度量方法。郭静等人将社交网络中用户的历史行为日志看作样本,借鉴最大似然估计的思想对用户间影响力学习问题建模;并在在线性阈值模型的框架下,提出一种影响力传播权重的计算方法。邓小龙等人提出了_一种新颖的基于轴节点选择策略的大图重要节点中介度近似计算方法和原型系统,并通过模拟数据和真实数据(包含一个连续六个月的真实社交网络数据集)进行了验证。在机器学习方法的应用方面,曹玖新等人使用朴素贝叶斯NaiveBayes、逻辑回归logisticsRregerssion等分类方法基于用户属性、社交关系和微博内容三类综合特征,对给定微博的用户转发行为进行预测。叶娜等人针对识别社交网络用户时存在的模式不一致问题,提出了基于分块和二部图的用户识别算法。李勇军等人以论文合作网络为基础,依据学生发表论文时通常与导师共同署名的现象,抽象出能够反映导师一学生合作关系的特征,并提出基于最大熵模型的导师一学生关系识别算法。张玉清等人从基于行为特征、基于内容、基于图( Graph)、无监督学习四个方面对近年来社交网络中异常帐号检测方案进行系统性的归纳总结,并对未来异常帐号检测的研究趋势进行了展望。
1基于通联数据的人际关系网络构建
1.1实体抽取
使用字典驱动方式对于结构化的通联数据进行实体抽取,实体抽取的原则是实体本身具有唯一性,并能够唯一表现该实体的特征,实体本身不能是孤立的,要和其他实体存在关联关系,实体属性要依附于实体本身,可以补充实体的特征和关联关系。通过随机生成方式,模拟出—万条数据样例,并且从通联数据本身的特点出发,选择出需要的实体。
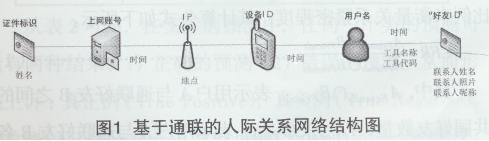
1)用户标识:模拟数据中随机产生了四种可以当作实体的字段,包括手机号码,邮箱,QQ账号以及为模拟数据生成的用户唯一标识。对于用户名实体需要添加账号类型的属性,对帐号的类别加以区分。同时用户标识会存在一些可串联的关联实体,例如,设备号、证件号、上网账号、用户名和IP地址。
2)好友标识:通联数据中关系好友的邮件信息用来唯一标识该好友,对于少量缺失情况标识实体需要补充记录ID。此举可避免同一节点对象由于采用不同标识而被视为不同的节点,进而保证人际关系网络的完整性,抽取结果如表1所示。

1.2实体关系抽取
实体间存在着紧密的连接关系,例如,证件号码和上网账号两个实体间在规定时间区间内是一对一的关系,一个证件号只能拥有唯一一个上网账号,一个上网账号只能依附于一个身份证号,同时上网账号可以串联出此账号拥有的IP,通过IP可以关联出此IP下所使用的设备情况,进一步完成对于用户虚拟身份的串联。通过用户名这一个实体就可以很容易的构建用户的好友网络,从而扩展出大的用户关系网。对于实体间关系的描述主要从时间维度出发,而与好友的实体关系还可以通过不同的上传工具进行分类,总体抽取结果如图1所示。
2基于支持向量机的人际关系预测
利用中文分词、自然语言处理等文本挖掘技术,对通联数据中能够反映人与人之间人际关系的文本数据进行分析处理。首先提取诸如同事、朋友、同学、家人等反映人际关系的特定词语,然后以此类词语作为节点间边的属性来构建人际关系网络。其次以通联记录、短信来往记录等信息为基础设计分类特征。最后利用在小样本下具有复杂决策边界建模能力的支持向量机( Suppport Vector Machine,SVM)进行训练得到适用于人际关系预测的分类模型,并用于未知关系的预测。
2.1人际关系预测模型的建立
为了预测人际网络中的两个自然人是否存在亲属、朋友或其他关系,本文通过分析现有具有特定人际关系的用户之间和无关系用户之间的行为特征差异,设计几种具有良好分类能力的属性作为分类特征,进而构建训练样本,并将是否存在关系及存在关系类别的判定转换成数据挖掘中的分类问题。
2.1.1特征选择
1)共同好友数量占好友总数的比率CFR
KOSSINETS等人通过研究在校大学生之间的熟人关系网络,发现他们之间的共同熟人数目在很大程度上决定两人之间是否存在联系,即共同熟人数越多则两人也为熟人的可能性就越大。显然两个自然人之间的共同好友数量越多,他们之间存在好友关系的可能性越大,相反则越小。
但是单纯以共同好友数量来衡量两个自然人之间关系的紧密程度存在明显的缺陷。假设用户A与用户B之间的共同好友数量为5,但用户A的好友总数为30而用户B的好友总数为100那么用户A存在与其剩余的其他25个好友更为紧密的可能性,同样用户B同样存在与其剩余的其他5个好友关系更为紧密的可能性,但是好友总数更多的用户A,其可能性更大。为了避免此种可能性的影响,利用好友总数为基数,利用共同好友数量占各自好友总数的比例来衡量关系紧密程度,其计算公式如下所示。

2)平均通联次数AR
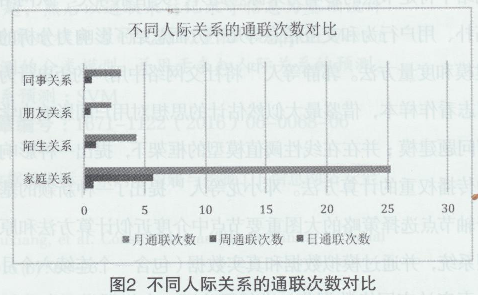
AR是指在观测数据范围内,两个用户之间通联次数。分别统计出现有数据中人物之间的日平均通联次数、周平均通联次数及月平均通联次数,在不同人际关系之间进行对比,取三者中分类能力最强的指标来表征平均通联次数,如图2所示,其计算公式如下所示。

3)平均通联时长ATR
仅仅从用户之间平均通联次数,不足以区分用户的关系紧密程度。例如,用户A与用户B之间的通联次数与用户B与用户C之间的通联次数相同,但用户B与用户C之间的通联时长更长,显然后者的关系更为紧密。所以有必要引入平均通联时长作为分类特征,该特征指在观测数据范围内,两个用户之间通联的平均时长,单位为秒,如图3所示。其计算公式如下所示。


4)平均消息交互次数AM
AM是指在观测数据范围内,两个用户之间发送消息的次数。同样分别统计出现有数据中人物之间消息交互的日平均、周平均及月平均次数,在不同人际关系之间进行对比,取三者中分类能力最强的的指标来表征平均消息交互次数,其计算公式如下所示。

本文设计的4大类特征依人际关系的远近呈规律性变化,即人际关系越紧密其通联次数及通联时长数值越大,而人际关系越疏远其通联次数及通联时长数值越小。例如“家庭关系”之间通联时长、通联次数均远远大于其他两类关系,且不同关系之间存在着一定的差异。可见,上诉4大类特征可以在一定程度上区分不同的人际关系,从而用于人际关系预测模型的训练。
2.1.2训练样本的构建
获取两两自然人之间的通联记录数据、消息信息及其他信息数据,分别依据2 .1.1节确立的计算方法进行计算得到共同好友数量、平均通联次数、平均通联时长、平均消息交互次数4个分类特征,得到初步的训练样本,数据形态如图4所示。
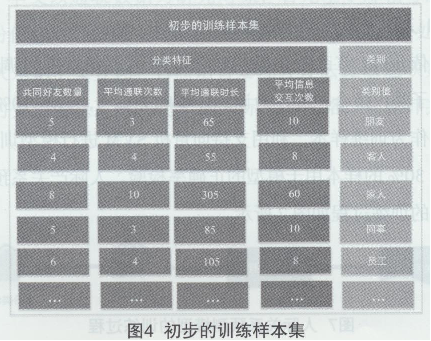
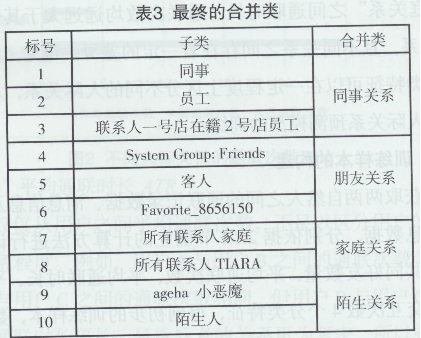
由于通联日志对于关系表述不一致。例如,朋友、客人这两类完全可以合并为同一类处理,将其命名为“朋友”类(合并前的类称为原始类,合并后的大类称为最终类)。这样避免出现大量相近的类别,大大提高训练样本的质量。
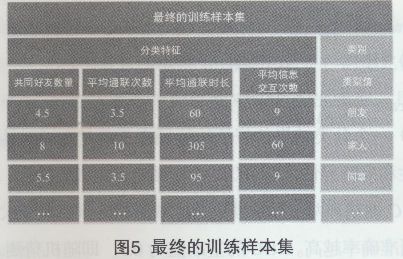
本文对上述初步的训练样本运用层次聚类进行类的合并。处理原则如下:1)利用层次聚类的类别可控特点,人工干预类的合并,进一步提高类的质量;2)合并后的最终类各样本的特征值由合并类中所有原始类中各特征值的平均值计算得到。其处理结果如图5所示,“朋友”、“客人,’被合并为同一类“朋友”类,“同事”、“员工”被合并为同一类“同事”类,其样本值为各自原始类中样本值的平均值。
2.2算法的正确率验证
本文中的人际关系预测只针对在通联中已建立好友关系但是具体存在何种关系类型未知的情况作为预测,这是一种分类问题。在预测过程中,为保证预测算法的有效性,本文将采用K折交叉验证评估方法。K折交叉验证:将初始样本分割成K个集合,其中一个单独的子样本作为验证模型的数据,其他K-1个样本作为训练集。为交叉验证需重复K次,每次针对一个子样本验证一次,并将平均K次的结果作为本算法的预测准确率。
本文采用多种评价方法对本预测算法进行评价,包括精确率、召回率、及F-Measure。下面以二元分类问题的混淆矩阵来说明以上几个评价指标的含义。
假设人际关系只有两种:“朋友”,“亲人’。
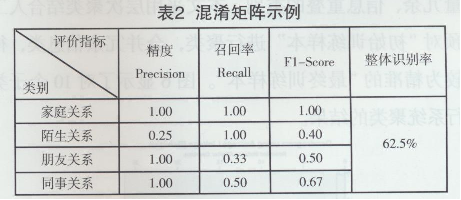
从表2可知,在实际的预测中,任何一个类的预测可能有两种结果,1)正确的预测;2)错误的预测。从而形成上诉:真正例( True Positive),真负例(True Negative),假负例( False Negative)及假正例(False Positive)的情况。同时,当真正例( True Positive)、真负例(True Negative)的比率较高时,就意味着模型整体的预测正确率就高,在混淆矩阵中表现为数值集中在矩阵的主对角线上。正确率、精确率、召回率和AUC的计算方法如下所示。
1)正确率:反映所有类的预测正确率,即整体识别率。
![]()
2)精确率:标记为正类的元组实际为正类的所占的百分比,在上例中表示为所有“朋友关系”被预测的比例,即

4) 一个分类结果的好坏的特征在于其是否同时具有高敏感性和高特异性,而AUC恰好结合了两者的特性。AUC是ROC曲线和两坐标轴围成的区域面积,该面积越大则表示预测准确率越高。AUC的基准值为0.5,即随机猜测。
3实例分析
3.1基于层次聚类的训练样本的构建
模拟出通联数据后,首先利用中文分词、自然语言处理等技术提取通联中的好友分组信息,然后以两两通联好友为计算对象,分别计算两个好友的共同好友数量占好友总数的比率CFR、平均通联次数AR、平均通联时长ATR及平均消息交互次数AM,得到‘初始训练样本”的4个分类特征。
由于不同的通联工具,其分组标识各不相同,并且用户可自定义分组信息,这必将导致出现大量的分组,即出现大量的分类类别。如:“同学”,“同事”,“好友”,“员工”,“同事”等。显然,“员工”和“同事”这两个子类在一定程度上是可以合并处理的,从而避免在使用分类算法时,出现大量冗余、信息重叠的类别。本文采用层次聚类结合人工干预对“初始训练样本”进行聚类,合并冗余信息类,得到较为精准的“最终训练样本”。图6显示了对10个子类进行系统聚类的结果。
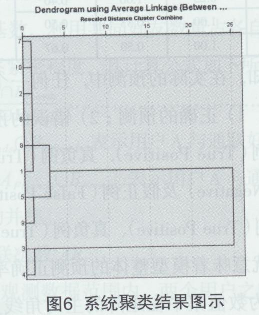
由图6可知,当聚类为3时,子类System Group:Friend。、同事、所有联系人一号店在籍2号店员工、客人、员工及Favorite_8656150共6个子类被合并为l类,陌生人、ageha小恶魔被合并为1类,所有联系人TIARA、所有联系人家庭被合并为1类。
聚类的结果较为合理,分类特征值较为相近的子类被合并为一个大类,所有联系人TIARA、所有联系人家庭是2个沟通交流较为频繁的子类,而陌生人、ageha小恶魔为2个沟通频较低2个子类。鉴于本文的研究对象,本文将系统聚类的结果进一步进行调整,合并为4大类,其结果如下:
3.2基于SVM的人际关系预测模型构建
3.2.1人际关系预测模型训练
依据3.1节系统聚类的结果,对训练样本进行调整,合并子类,将合并类作为训练样本的类标号,选取70%的样本作为训练样本,利用支持向量机SVM进行模型训练,剩余30%的样本用于模型的正确率检验。人际产关系预测模型的训练过程如图7所示。

![]()
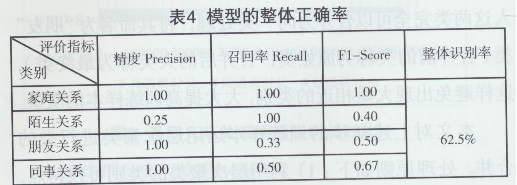
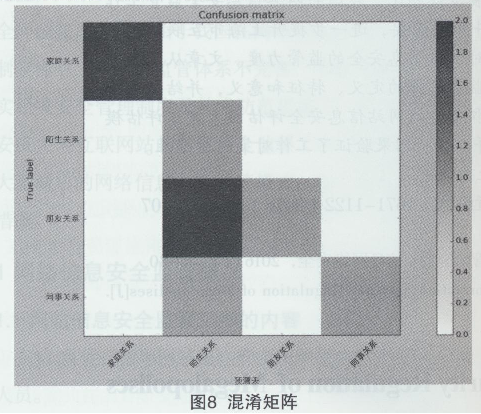
如表4所示,基于本文现有的训练数据,利用基于径向基核函数的支持向量机进行人际关于预测模型的预测,在现有数据中,共出现4中人际关系类型,分别是“家庭关系”,“陌生关系”,“朋友关系”,“同事关系”,模型的整体识别率为62.5%。同时,“家庭关系”及“同事关系”的预测较为精准,尤其是“家庭关系”其精度为100%,而“陌生关系”及“朋友关系”的预测准确率较低,“陌生关系”的精度仅为25%。如图8所示,混淆矩阵显示了本文提出的人际关系预测模型各个类的情况。
4结束语
本文以通联数据为研究对象,首先基于邮箱等虚拟身份信息对疑似同一对象的用户实体进行识别,并处理。其次采用中文分词、自然语言处理等方法提取通联数据中的分组信息,建立初步的人际关系网络,并设计共同好友数量占好友总数的比率CFR、平均通联次数AR等4个方面的特征,利用系统聚类,对训练数据进行聚类并结合人工干预合确定最终类及训练样本,从而消除通联分组信息的冗余,避免大量类的出现。然后在以上分析的基础上,利用适合小样本的支持向量机算法,进行模型训练,得到适合通联数据人际关系预测的分类模型。实验结果表明,本算法能够识别出网络中的全部比例“家庭关系”,并能从整体上保证相对较高的准确率,具有一定的应用价值。